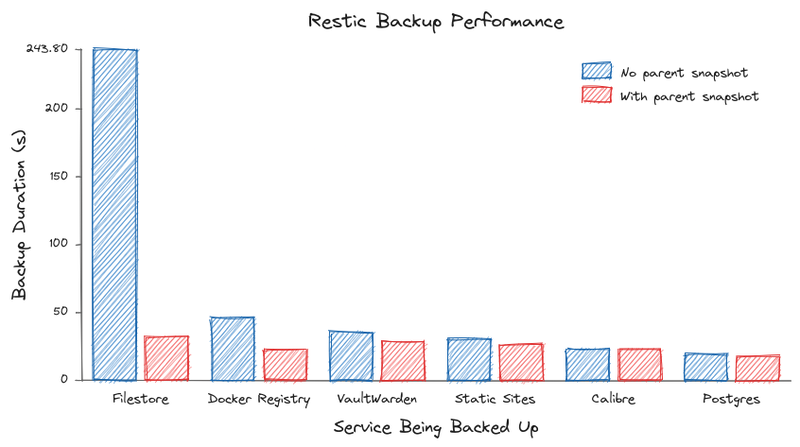
Chart built with Excalichart, explanation of results at the end
SPOILER: This is one of those optimization stories where the dramatic improvement comes from just not-doing the wrong thing anymore, as opposed to any feats of actual performance engineering. Basically just starting with an arbitrarily bad baseline. But still, this is a footgun one will run into naively configuring Restic on Kubernetes, thus the post.
TL;DR - If you're using Restic in your Kubernetes (K8s) cluster to make backups and seeing no parent snapshot found in your (verbose) logs, do one of the following things:
- Set
--group-by=paths- This is the Restic recommended option
- Set the
--hostflag to some constant (e.g.--host=foo-service)
Either of these will cause Restic to select a parent snapshot, which should avoid having to scan existing files to detect changes. More details are available in the Restic docs.
Okay, now the longer version:
A Suspicious Log Line
I was adding backups for a new service to my K8s cluster when I noticed a suspicious-looking line in the logs:
no parent snapshot foundNow, at this point I don't know what a 'parent snapshot' is, but I run backups nightly, so there should be plenty of previous (parent?) backups (snapshots?) to get inspiration from.
Around this time, I also notice that backups are still quite slow, even when not much has changed. E.g. even on days when I haven't added any files to my personal file store, the backups are taking five or six minutes, which seems highly suspect for an optimized piece of software like restic, which I know is capable of incremental backups by default.
After searching around for "no parent snapshot found" restic for a bit, I eventually got the gist: no parent snapshot found is like the restic-equivalent of SQL's full table scan: you read all the files on the local disk, and compare hashes against the existing repository of all snapshots to decide what has changed.
But we can be more efficient (with a caveat I'll address later): if we're on the same computer and doing an incremental backup, we can skip all the files that haven't been modified since the last time we checked. This will save us a ton of time scanning gigabytes (or more!) of files that we know haven't changed.
And this is how Restic works under normal conditions: every time you run the backup, it selects a parent snapshot using a set of heuristics.
Heurestics
The process Restic uses for selecting a parent snapshot is described in its docs, but by default, it looks for the latest snapshot covering the same set of paths, and with the same hostname.
This second one is what causes problems for our K8s-based backups, as the default hostname for a cronjob is something like:
<job name>-<timestamp>-<random suffix>And so every time we go to do a backup, all the previous snapshots are ruled out as candidates because each has a different hostname. As mentioned in the TL;DR, we can fix this by either setting the host to a constant with --host, or (the Restic recommended approach) of setting --group-by=paths to ignore the unstable hostname when selecting a parent snapshot.
Restic's default here makes sense for supporting the usecase of multiple computers syncing to the same repository with some overlapping set of shared files - you can't compare the timestamps if you're on a different computer, as the files may have been put there at different times or clocks could be out of sync, etc, etc.
But if we know our backup cronjob pods are doing backups from the same underlying volume mount every time, we can tell Restic to just rely on the paths, and trust the timestamps to determine which files we can safely ignore if present in the parent snapshot.
The Caveat
The caveat here is that using a parent snapshot seems to actually be slower for certain backup workloads. A few of the services I'm backing up are comprised of a bunch of small files, and it ends up being significantly faster (seconds vs minutes) to just let it scan the whole local directory versus load all the parent snapshot metadata. I think this is a pathology with slow downloads on the storage backend that I'm using (Backblaze), but still worth noting. Which is all to say: try tweaking the configs, doing multiple runs of different types (full, incremental, etc) and seeing what performs best.
And Finally, The Results
(See the chart at the top of the post)
As expected, services that store a lot of data in a lot of slow-changing files had the best gains, as we can skip reading all the already backed up data. My self-hosted Google Drive/Dropbox replacement and personal Docker image registry both fit that profile. For smaller repositories (<1 GB), the change is negligible.